I have become increasingly frustrated by the continued global reporting of highly misleading figures for the number of Covid-19 infections in different countries. Such “official” figures are collected in very different ways by governments and can therefore not simply be compared with each other. Moreover, when they are used to calculate death rates they become much more problematic. At the very least, everyone who cites such figures should refer to them as “Officially reported Infections”
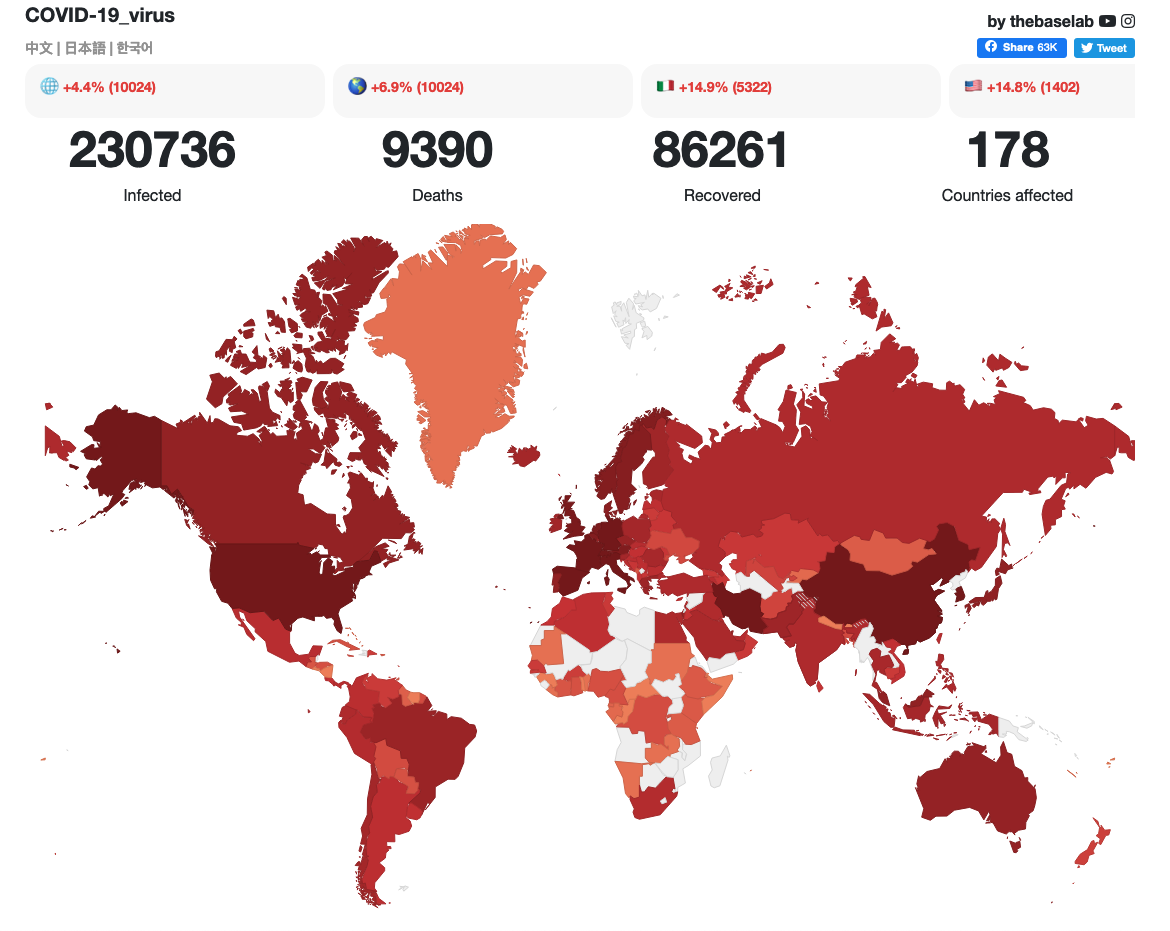
As I write (19th March 2020, 17.10 UK time), the otherwise excellent thebaselab‘s documentation of the coronavirus’s evolution and spread gives mortality rates (based on deaths as a percentage of infected cases) for China as 4.01%, Italy as 8.34% and the UK as 5.09%. However, as countries are being overwhelmed by Covid-19, most no longer have the capacity to test all those who fear that they might be infected. Hence, as the numbers of tests as a percentage of total cases go down, the death rates will appear to go up. It is fortunately widely suggested that most people who become infected with Covid-19 will only have a mild illness (and they are not being tested in most countries), but the numbers of deaths become staggering if these mortality rates are extrapolated. Even if only 50% of people are infected (UK estimates are currently between 60% and 80% – see the Imperial College Report of 16th March that estimates that 81% of the UK and US populations will be infected), and such mortality rates are used, the figures (at present rates) become frightening:
- In Italy, with a total population of 60.48 m, this would mean that 30.24 m people would be infected, which with a mortality rate of 8.34% would imply that 2.52 m people would die;
- In the UK, with a total population of 66.34 m, this would mean that 33.17 m people would be infected, which with a mortality rate of 5.09% would imply that 1.69 m people would die.
These figures are unrealistic, because only a fraction of the total number of infected people are being tested, and so the reported infection rates are much lower than in reality. In order to stop such speculations, and to reduce widespread panic, it is essential that all reporting of “Infected Cases” is therefore clarified, or preferably stopped. Nevertheless, the most likely impact of Covid-19 is still much greater than most people realise or can fully appreciate. The Imperial College Report (p.16) thus suggests that even if all patients were to be treated, there would still be around 250,000 deaths in Great Britain and 1.1-1.2 m in the USA; doing nothing, means that more than half a million people might die in the UK.
Having accurate data on infection rates is essential for effective policy making and disease management. Globally, there are simply not enough testing kits or expertise to be able to get even an approximately accurate figure for real infections rates. Hence, many surrogate measures have been used, all of which have to make complex assumptions about the sample populations from which they are drawn. An alternative that is fortunately beginning to be considered is the use of digital technologies and social media. Whilst by no means everyone has access to digital technologies or Internet connectivity, very large samples can be generated. It is estimated that on average 2.26 billion people use one of the Facebook family of services every day; 30% of the world’s population is a large sample. Existing crowdsourcing and social media platforms could therefore be used to provide valuable data that might help improve the modelling, and thus the management of this pandemic.
Crowdsourcing
[Great to see that since I first wrote this, Liquid Telecom has used Ushahidi to develop a crowd sourced Covid-19 data gathering initiative]
The violence in Kenya following the disputed Presidential elections in 2007, provided the cradle for the development of the Open Source crowdmapping platform, Ushahidi, which has subsequently been used in responding to disasters such as the earthquakes in Haiti and Nepal, and valuable lessons have been learnt from these experiences. While there are many challenges in using such technologies, the announcement on 18th March that Ushahidi is waiving its Basic Plan fees for 90 days is very much to be welcomed, and provides an excellent opportunity to use such technologies better to understand (and therefore hopefully help to control) the spread of Covid-19. However, there is a huge danger that such an opportunity may be missed.
The following (at a bare minimum) would seem to be necessary to maximise the opportunity for such crowdsourcing to be successful:
- We must act urgently. The failure of countries across the world to act in January, once the likely impact of events in Wuhan unravelled was staggering. If we are to do anything, we have to act now, not least to help protect the poorest countries in the world with the weakest medical services. Waiting even a fortnight will be too late.
- Some kind of co-ordination and sharing of good practices is necessary. Whilst a global initiative might be feasible, it would seem more practicable for national initiatives to be created, led and inspired by local activists. However, for data to be comparable (thereby enabling better modelling to take place) it is crucial for these national initiatives to co-operate and use similar methods and approaches. There must also be close collaboration with the leading researchers in global infectious disease analysis to identify what the most meaningful indicators might be, as well as international organisations such as the WHO to help disseminate practical findings..
- An agreed classification. For this to be effective there needs to be a simple agreed classification that people across the world could easily enter into a platform. Perhaps something along these lines might be appropriate: #CovidS (I think I might have symptoms), #Covid7 (I have had symptoms for 7 days), #Covid14 (I have had symptoms for 14 days), #CovidT (I have been tested and I have it), #Covid0 (I have been tested and I don’t have it), #CovidH (I have been hospitalised), #CovidX (a person has died from it).
- Practical dissemination. Were such a platform (or national platforms) to be created, there would need to be widespread publicity, preferably by governments and mobile operators, to encourage as many people as possible to enter their information. Mutiple languages would need to be incorporated, and the interfaces would have to be as appealing and simple as possible so as to encourage maximum submission of information.
Ushahidi as a platform is particularly appealing, since it enables people to submit information in multiple ways, not only using the internet (such as e-mail and Twitter), but also through SMS messages. These data can then readily be displayed spatially in real time, so that planners and modellers can see the visual spread of the coronavirus. There are certainly problems with such an approach, not least concerning how many people would use it and thus how large a sample would be generated, but it is definitely something that we should be exploring collectively further.
Social media
An alternative approach that is hopefully also already being explored by global corporations (but I have not yet read of any such definite projects underway) could be the use of existing social media platforms, such as Facebook/WhatsApp, WeChat or Twitter to collate information about people’s infection with Covid-19. Indeed, I hope that these major corporations have already been exploring innovative and beneficial uses to which their technologies could be put. However, if this if going to be of any real practical use we must act very quickly.
In essence, all that would be needed would be for there to be an agreed global classification of hashtags (as tentatively suggested above), and then a very widespread marketing programme to encourage everyone who uses these platforms simply to post their status, and any subsequent changes. The data would need to be released to those undertaking the modelling, and carefully curated information shared with the public.
Whilst such suggestions are not intended to replace existing methods of estimating the spread of infectious diseases, they could provide a valuable additional source of data that could enable modelling to be more accurate. Not only could this reduce the number of deaths from Covid-19, but it could also help reassure the billions of people who will live through the pandemic. Of course, such methods also have their sampling challenges, and the data would still need to be carefully interpreted, but this could indeed be a worthwhile initiative that would not be particularly difficult or expensive to initiate if global corporations had the will to do so.
Some final reflections
Already there are numerous new initiatives being set up across the world to find ways through which the latest digital technologies might be used in efforts to minimise the impact of Covid-19. The usual suspects are already there as headlines such as these attest: Blockchain Cures COVID-19 Related Issues in China, AI vs. Coronavirus: How artificial intelligence is now helping in the fight against COVID-19, or Using the Internet of Things To Fight Virus Outbreaks. While some of these may have potential in the future when the next pandemic strikes, it is unlikely that they will have much significant impact on Covid-19. If we are going to do anything about it, we must act now with existing well known, easy to use, and reliable digital technologies.
I fear that this will not happen. I fear that we will see numerous companies and civil society organisations approaching donors with brilliant new innovative “solutions” that will require much funding and will take a year to implement. By then it will be too late, and they will be forgotten and out of date by the time the next pandemic arrives. Donors should resist the temptation to fund these. We need to learn from what happened in West Africa with the spread of Ebola in 2014, when more than 200 digital initiatives seeking to provide information relating to the virus were initiated and funded (see my post On the contribution of ICTs to overcoming the impact of Ebola). Most (although not all) failed to make any significant impact on the lives and deaths of those affected, and the only people who really benefitted were the companies and the staff working in the civil society organisations who proposed the “innovations”.
This is just a plea for those of us interested in these things to work together collaboratively, collectively and quickly to use what technologies we have at our fingertips to begin to make an impact. Next week it will probably be too late…